7장. 서비스 탐색
서비스 탐색이란 특정 프로세스가 서비스를 위해 리스닝하고 있는 주소를 찾는 데 도움을 주는 도구다.
좋은 서비스 탐색 시스템은 서비스 정보를 빠르고 신뢰성 있게 제공하고, 대기 시간이 짧아 서비스와 관련된 정보가 변경되면 곧 바로 클라이언트에게 업데이트해준다. 그리고 해당 서비스가 무엇인지에 대한 풍부한 정의(포트 정보 등)를 저장할 수 있다.
대부분의 전통적인 네트워크 인프라의 경우 쿠버네티스의 동적 시스템을 지원하기 어렵다. 서비스 탐색 도구는 이를 도와준다.
DNS(Domain Name System)은 인터넷에서 사용하는 전통적인 서비스 탐색 시스템이다. 광범위하고 효율적인 캐싱을 통해 안정적인 이름 확인(name resolution)을 위해 설계됐다.
대다수의 시스템(eg. java)에서는 DNS 조회 후 캐싱된 데이터를 활용하기 때문에 쿠버네티스의 동적인 환경(파드의 IP가 계속 변경됨)에는 부적합하다.
서비스 객체
서비스 객체란 쿠버네티스에서 서비스 탐색을 수행하는 오브젝트이다.
kubectl expose 명령을 통해 쉽게 서비스 객체를 생성할 수 있으며 이는 해당 객체의 레이블을 셀렉터로 가지는 서비스 객체를 생성한다.
kubectl create deployment으로 디플로이먼트를 쉽게 생성하는 방식과 유사하다.
$ kubectl create deployment alpaca-prod \
--image=gcr.io/kuar-demo/kuard-amd64:blue \
--port=8080
$ kubectl scale deployment alpaca-prod --replicas 3
$ kubectl expose deployment alpaca-prod
$ kubectl create deployment bandicoot-prod \
--image=gcr.io/kuar-demo/kuard-amd64:green \
--port=8080
$ kubectl scale deployment bandicoot-prod --replicas 2
$ kubectl expose deployment bandicoot-prod
$ kubectl get pods -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
alpaca-prod-698b96c7f5-56xt5 1/1 Running 0 21s 10.244.2.2 my-cluster-worker3 <none> <none> app=alpaca-prod,pod-template-hash=698b96c7f5
alpaca-prod-698b96c7f5-5tmsq 1/1 Running 0 27s 10.244.3.3 my-cluster-worker <none> <none> app=alpaca-prod,pod-template-hash=698b96c7f5
alpaca-prod-698b96c7f5-wwqqk 1/1 Running 0 21s 10.244.1.2 my-cluster-worker2 <none> <none> app=alpaca-prod,pod-template-hash=698b96c7f5
bandicoot-prod-7ddd47b959-6vbh7 1/1 Running 0 13s 10.244.1.3 my-cluster-worker2 <none> <none> app=bandicoot-prod,pod-template-hash=7ddd47b959
bandicoot-prod-7ddd47b959-zbm5r 1/1 Running 0 16s 10.244.3.4 my-cluster-worker <none> <none> app=bandicoot-prod,pod-template-hash=7ddd47b959
$ kubectl get services -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
alpaca-prod ClusterIP 10.96.78.232 <none> 8080/TCP 63s app=alpaca-prod
bandicoot-prod ClusterIP 10.96.191.162 <none> 8080/TCP 55s app=bandicoot-prod
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 16h <none>
서비스 객체는 셀렉터에 레이블 조건을 지정하고 서비스와 통신할 수 있는 포트를 지정한다.
서비스에는 클러스터 IP(Cluster IP)라는 가상 IP가 할당된다.
파드와 상호작용하기 위해서는 아래처럼 포트포워딩을 수행하고 localhost:48858로 접속해 확인할 수 있다.
$ ALPACA_POD=$(kubectl get pods -l app=alpaca-prod \
-o jsonpath='{.items[0].metadata.name}')
$ kubectl port-forward $ALPACA_POD 48858:8080
서비스 DNS
클러스터 IP는 가상의 IP 주소로 안정적이며 캐싱 가능하여 DNS 주소로 제공할 수 있다.
쿠버네티스는 클러스터에서 실행되는 파드에 DNS 서비스를 제공한다.
쿠버네티스 DNS 서비스는 클러스터 IP에 대한 DNS 이름을 제공하며 클러스터를 처음 생성할 때 시스템의 구성 요소로 설치된다.
$ dig alpaca-prod.default.svc.cluster.local
;; opcode: QUERY, status: NOERROR, id: 12071
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;alpaca-prod.default.svc.cluster.local. IN A
;; ANSWER SECTION:
alpaca-prod.default.svc.cluster.local. 30 IN A 10.115.245.13
DNS 전체 이름 구성은 아래와 같다.
- alpaca-prod
- 서비스 객체의 이름
- default
- 서비스 객체가 속한 네임스페이스
- svc
- 서비스 객체임을 표기. 다른 타입도 지원 가능
- cluster.local.
- 클러스터의 기본 도메인 이름
참고
쿠버네티스 DNS 서버로의 질의는 nslookup으로 가능하다.
$ cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local dns.podman
nameserver 10.96.0.10
options ndots:5
$ nslookup alpaca-prod 10.96.0.10
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: alpaca-prod
Address 1: 10.96.78.232 alpaca-prod.default.svc.cluster.local
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alpaca-prod ClusterIP 10.96.78.232 <none> 8080/TCP 16m
Readiness probe
서비스 객체는 준비 검사(Readiness probe)에 실패한 파드를 요청 대상에서 제거한다.
아래처럼 Readiness probe를 추가하고 endpoints를 모니터링할 수 있다.
$ kubectl edit deployment/alpaca-prod
$ kubectl get endpoints alpaca-prod --watch
spec:
template:
spec:
containers:
- name: alpaca-prod
readinessProbe:
httpGet:
path: /ready
port: 8080
periodSeconds: 2
initialDelaySeconds: 0
failureThreshold: 3
successThreshold: 1
클러스터 외부로의 서비스
NodePorts를 사용하면 간단하게 클러스터 외부에서 내부를 접속할 수 있다.
아래처럼 kubectl edit을 사용하거나 kubectl expose시 --type=NodePort 플래그를 지정해 생성할 수 있다.
$ kubectl edit deployment/alpaca-prod
spec:
type: NodeProt
NodePort가 노출되면 SSH 터널링을 사용할 수 있다.
$ ssh <노드> -L 8080:localhost:32711
로드밸런서 연계
외부 로드밸런서와 연계할 수 있는 클러스터가 있는 경우 LoadBalancer 타입을 사용할 수 있다.
$ kubectl edit deployment/alpaca-prod
spec:
type: LoadBalancer
고급 세부 정보
엔드포인트
엔드포인트는 서비스의 클러스터 IP와 같은 방식이 아닌 직접 연결할 수 있는 객체이다.
서비스 객체를 생성할 때 엔드포인트(Endpoint) 객체도 함께 생성된다.
수동 서비스 탐색
쿠버네티스 API와 통신해 각 파드에 할당된 IP를 확인할 수 있다.
$ kubectl get pods -o wide --show-labels
kube-proxy와 클러스터 IP
클러스터 IP는 서비스의 모든 엔드포인트에 트래픽을 로드밸런싱하는 안정적인 가상 IP다.
kube-proxy가 이를 수행하는데, kube-proxy는 클러스터의 모든 노드에서 실행된다.
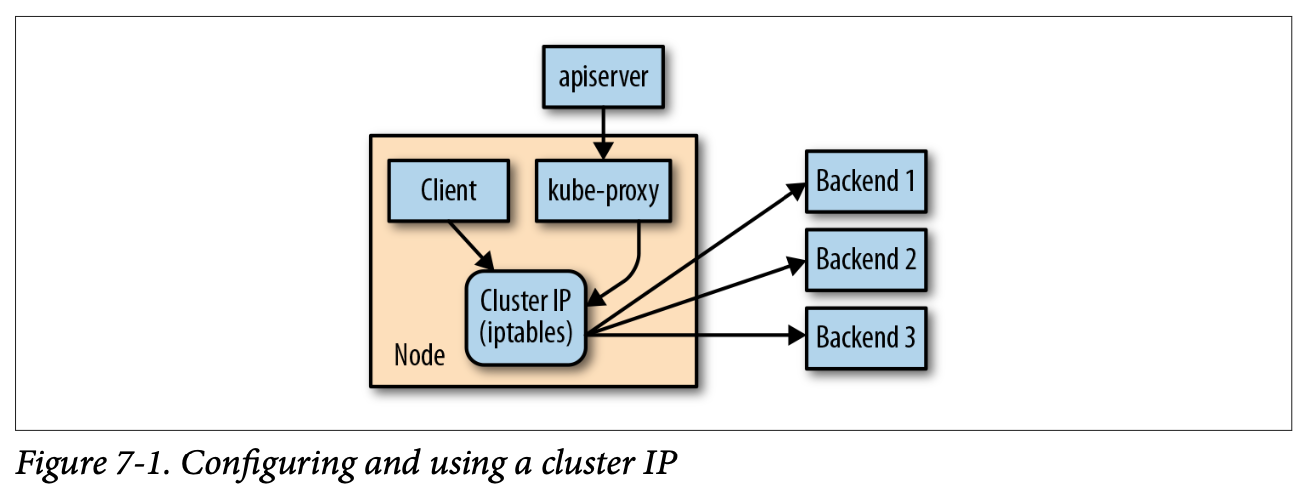
kube-proxy는 API 서버를 통해 클러스터의 새로운 서비스를 감시한다.
그 다음 해당 호스트의 커널에서 iptables 규칙 집합을 프로그래밍해 패킷의 목적지를 재작성하고, 해당 서비스의 엔드포인트 중 하나를 향하게 한다.
API 서버는 서비스가 생성될 때 클러스터 IP를 할당한다. 사용자가 지정할 수도 있다.
클러스터 IP는 삭제하지 않으면 그대로 유지된다.
클러스터 IP 환경 변수
파드의 환경 변수에 ALPACA_PROD_SERVICE_HOST, ALPCA_PROD_SERVICE_PORT와 같은 이름으로 서비스 탐색 정보가 설정된다.